



May 20, 2013 , by
Public Summary Month 5/2013
At the current stage of the project several incremental milestones have been achieved. First of all, robust person detection, combining several computer vision techniques. Secondly, face, facial feature and facial expression detection and tracking. Then, body part detection, tracking and body expression coding. And finally perform the user body expression analysis for intended and non-intended gestures. See Figure 1 for an overview of the process.
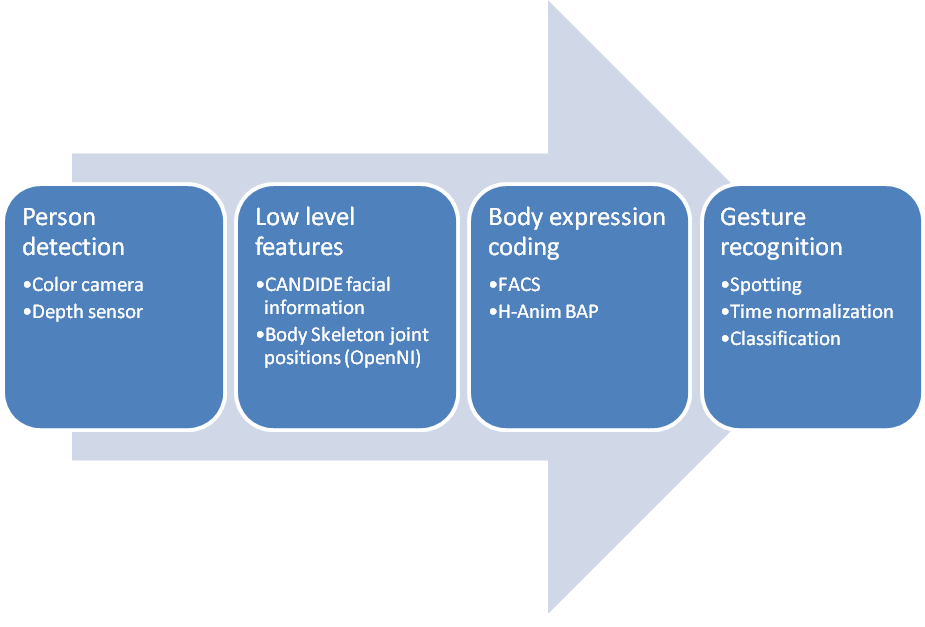
Figure 1: Body expression analysis procedure
The proper composition of gestures classifies to couple with intended and non-intended gestures, but especially the validation of every computer vision module separately has been the focus of work for the last two months. The details of this evaluation can be seen in the deliverable D4.1. Apart from this evaluation we show here the improvements we have added to the planned strategies for human detection and scene interpretation in the last two months.
Dec 14, 2012 , by
Public Summary Month 12/2012
In the previous months the work has been devoted to the encoding of facial expressions in a coherent, accurate and efficient manner using FACS. After achieving a satisfactory result, then the target of the work has moved to the rest of the body.
During the last two months the work has been focused on obtaining a suitable low-level and compact body pose coding system from a set of body joint positions and rotations. This is the first step towards a more abstract and dynamic body expression coding.
Previously, in the preliminary stage, that is, the capture phase, and specifically for the detection and tracking of the body parts, a Microsoft Kinect camera and the OpenNI/NITE software are being used. This approach is one of the most robust human body part trackers currently available. This human tracker provides the position and rotation of a set of particular body joints, and the connectivity among them, denoted as skeleton. However, and in order to increase future compatibility, we also consider other alternatives for the tracking of the body parts. In order to achieve it, we perform an abstraction of the so called skeleton, to fulfil the H-Anim standard specification, which describes a body skeleton configuration, including a standardized hierarchical structure of joints, with a predefined set of joint names and local and global coordinate system configurations. In this way, the input for our coding system will be a skeleton in the H-Anim standard. Thus, the static body part configurations are encoded as body part postures at each frame, using the coding system presented next.
Oct 9, 2012 , by
Public Summary Month 10/2012
We have been improving the facial tracker in order to make it more robust than the original version to sudden illumination changes. The improvements have been focused principally in the learning strategy of the facial template for the calculation of the update of the 3D facial model configuration. Its previous version was simply built with the mean and standard deviations of the pixel values in the warped facial image of the most recent frames. Currently, the learning process takes into account which frames can be considered as good enough to take them as a reference. The frontal-like views which do not have too many pixel outliers (i.e, those which could have been occluded by other objects, such hands or hair) are only considered with a more immediate learning time so that it can adapt to sudden illumination changes.
On the other hand, we have also defined a 3D facial model derived from Candide-3, with 14 DOFs (degrees of freedom) from which 12 (all except the XY position with respect to the screen) are related to facial AUs (Action Units) of the FACS (Facial Action Coding System): head forward/back (AU57/58), head up/down (AU53/54), head turn left/right (AU51/52), head tilt left/right (AU55/56), left eye closed (AU42/43/44/45), right eye closed (AU42/43/44/45), brow lowerer (AU4), outer left brow raiser (AU2), outer right brow raiser (AU2), mouth opener (AU10/26/27), lip stretcher (AU20) and lip corner depressor (AU13/15).
Regarding the recognition of dynamic gestures, during this period we have finished the C++ implementation of the ACA algorithm presented in the last report, which was originally coded in Matlab, obtaining the same segmentation results with the same parameters. Therefore, this implementation is ready to be integrated in the Kompaï robotic platform in subsequent stages of the project.
Besides, we have been reviewing coding systems for body expression, with a similar scope to that of the well-known FACS for facial expressions, and we have seen that the The Body Action and Posture Coding System (BAP) proposed by Dael et al. can be appropriate for our purpose. We consider establishing a relation between the body data tracked by our system and the BAP and FACS coding for fused expression recognition following the approach of the statistical tool of the Canonical Correlation Analysis (CCA). We will use the annotation tool ANVIL to create the ground truth for the recognition.
Aug 28, 2012 , by
Public Summary Month 8/2012
During the last two months the work has been focused on the scientific and technical aspects regarding person detection and tracking, and gesture spotting.
For the person detection, the work is further divided into face detection and tracking and body features detection and tracking.
In face detection, the work has been focused on achieving an automatic initialization for an Active Appearance Model based facial feature tracking approach, which is a practical problem of this approach. A novel solution has been proposed using LBP and Haar-features to detect the face and eye regions. And once detected, the rest of the facial points corresponding to the eyebrows, nose and the mouth are extracted. This approach improves the accuracy of facial point detection and performance since there is no need to generate and fit a model (AAM) with many parameters.
In body detection, the focus has been on removing the body detection and tracking limitations of OpenNI/NITE based body tracking implementation under difficult scenarios, such as people far away or too close to a wall. This improvement uses HOG descriptors and a pre-trained person detector, which provides a sparse detection (i.e. bounding box) which can be refined later on. And to improve the tracking procedure, a Rao-Blackwellized Data Association Particle Filter (RBDAPF) has been implemented, which can couple with sparse detections.
The body and face detection provides a constant flow of features set representing the pose and facial expressions. These information needs to be processed in order to recognize the body expression. Gesture spotting refers to the procedure of dividing a time series of features containing a set of a priori unknown set of gestures into non-overlapping pieces containing only one gesture each. The output pieces of this procedure are then classified into gestures. Two different algorithms for gesture spotting are being implemented which improve over the state of the art: Aligned Cluster Analysis (ACA) and its extension Hierarchical Aligned Cluster Analysis (HACA). Additionally, Y-Means is being implemented as a possible improvement over HACA/ACA algorithms or as alternative to them.
Aug 21, 2012 , by
Public Summary Month 6/2012
The last two month work consists in analyzing the system and its capabilities in order to define scenarios that will point out the developments done for the project.
Test Scenarios
Test case 1
The purpose of this test is to check the person behavior monitoring vision system alone. For this purpose the next test case scenario is proposed in the context of the practical scenario.
Mary is sitting, playing a game with the robot, so the robot is watching at her face and analyzes the facial expressions and the pose of the head. Suddenly Mary stops playing and her facial expression changes. She’s having a heart attack. Kompaï detects a strange behavior (e.g. she’s shaking) and signs of negative emotions in her face (e.g. fear, disgust). So Kompaï sends an alert to the caregiver.
Test Case 2
The purpose of this second case is to test the combination of the autonomous navigation of the Kompaï robot at home and the monitoring vision system. Two sub cases are proposed, one for a positive response and the other one for an emergency situation:
1. Mary gets a videoconference call from Kompaï but does not go to the robot to answer it. Later on, she receives a second call and she does not answer to it either. Therefore, the robot starts a patrol around the house and finds her at the kitchen. She is cooking, so she didn’t hear the calls, but she is ok. The robot approaches to hear and asks if she is ok. Then she realizes that the robot is there, turns around and makes the “everything ok” gesture.
2. Mary gets a videoconference call from Kompaï but does not go to the robot to answer it. Later on, she receives a second call and she does not answer to it either. Therefore, the robot starts a patrol around the house and finds her at the kitchen. She is laying on the floor and the robot detects her presence. The robot approaches to hear and asks if she is ok. Kompaï does not receive any response, and after analyzing her pose, facial expression and environment, decides that she is in trouble and sends an emergency alarm.



